
随着科技的不断发展,越来越多的领域运用神经网络进行深度学习来解决问题。与传统的方法不同,深度学习依赖于大量数据进行训练,来发现隐藏的关系模式和相关性,并以此建模和优化。因此,该方法的有效性很大程度上取决于数据量的大小。然而,自然科学中的大多数问题不太适合这种方法。所以,急需开发新的需要数据量小的方法来解决上述问题。
减轻对数据的依赖的一种方法是迁移学习(TL),它指在已进行过预训练的神经网络上进行微调。相关研究验证了该方法在自然科学领域中的部分工作的有效性。但是,大多数工作项目来自于不同的源数据,导致靶向问题与源数据不匹配,限制了TL的效果。另一种方法则是自我监督学习(SSL)技术,它与TL的主要区别是,在预训练阶段使用未标记的数据,以避免对模型有效性的影响。
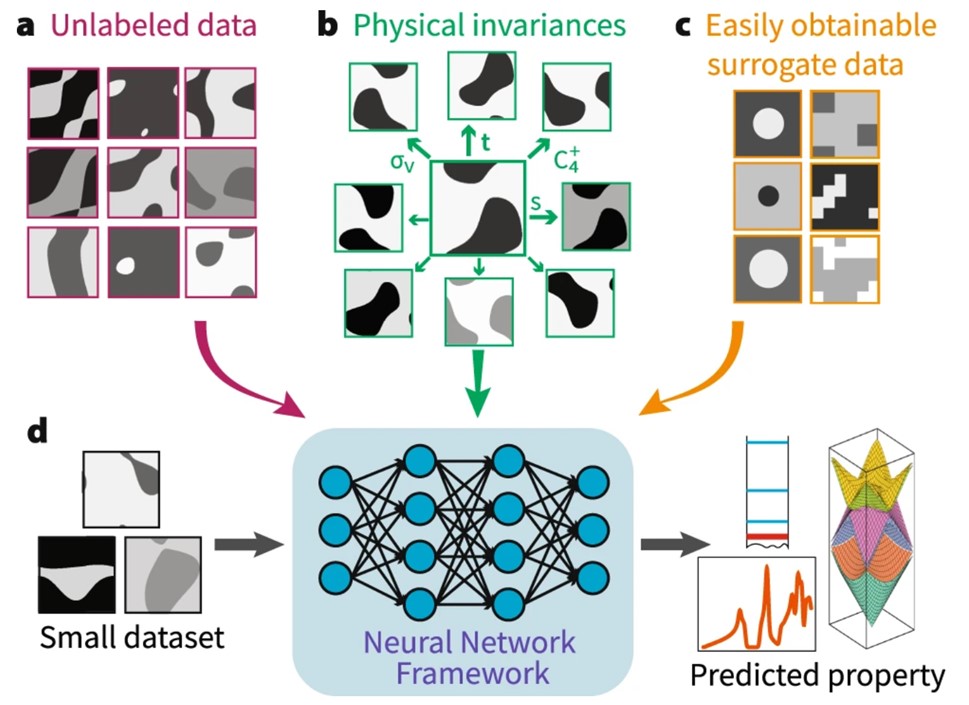
近日,麻省理工的Charlotte Loh等人提出了一种替代和不变性增强的对比学习(SIB-CL),它是一种基于自然科学中问题单独开发的深度学习框架,其中辅助信息源通常是先验的或可容易得到的。
本文要点:
1)该工作提出了一种替代和不变性增强的对比学习(SIB-CL)技术,它具有以下几个特点:第一,该技术使用了大量未标记的数据;第二,该模型输入的均为先验性知识,即以物理不变性形式存在的公理,其可以由输入的几何对称性或问题的一般非对称性相关不变性来控制;第三,该技术还使用类似问题的代理数据集来进行训练,训练过程使用更为简化或近似的标记,生成成本更低。
2)该工作还进一步讨论了该SIB-CL的适用场景,其创建相关简化替代性数据集的特点,在数学领域中近似分析分支非常常见,其应用包括了原子间力场分析,泛函密度理论等。
Loh, C., Christensen, T., Dangovski, R. et al. Surrogate- and invariance-boosted contrastive learning for data-scarce applications in science. Nat Commun 13, 4223 (2022).
DOI:10.1038/s41467-022-31915-y
https://doi.org/10.1038/s41467-022-31915-y

















