蛋白质工程具有巨大的学术和工业应用潜力。然而,由于缺乏与设计目标相符的实验方法以及高通量方法来发现稀有的、强化变体而受到局限。有鉴于此,美国哈佛大学George M. Church等研究人员,利用高效数据挖掘研发出低氮蛋白工程方法。
本文要点
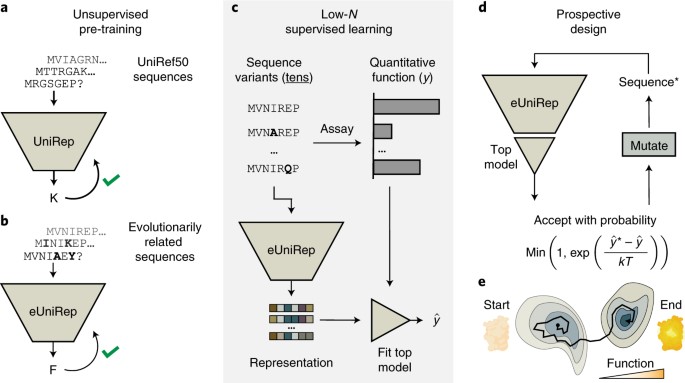
1)研究人员介绍了一种基于机器学习的算法,该算法可以使用多达24个经过功能分析的突变体序列来构建精准的虚拟环境,并通过计算机定向进化筛选一千万个序列。
2)正如对维多利亚水母的GFP(avGFP)和大肠杆菌TEM-1β-内酰胺酶这两种不同的蛋白质进行测试,通过单轮筛选的最优候选物是多样的,并且与先前的高通量研究中所获得的工程突变体一样活跃。
3)通过从天然蛋白质序列图谱中提取信息,该模型学习了“非自然性”的潜在表示形式,这有助于引导检索远离非功能性序列的邻域。然后,利用低N筛选对所感兴趣的对象进行改进。
本文研究的算法可在不牺牲通量的情况下有效利用资源密集型数据进行高保真测定,并有助于加速工程蛋白应用于发酵罐、农业和临床。
参考文献:
Surojit Biswas, et al. Low- N protein engineering with data-efficient deep learning. Nature Methods, 2021.
DOI:10.1038/s41592-021-01100-y
https://www.nature.com/articles/s41592-021-01100-y

















